
When we look at the aims of continuous integration and continuous delivery processes, automating the build and deployment steps is never enough on it’s own, don’t get me wrong, it is of course a great start, but this does not solve all the daily problems teams will encounter. A continuous integration process in it’s purest form takes a code change, compiles it, runs unit tests on it, packages it, and then uploads it to an artifact repository. The continuous integration process then hands over to continuous delivery, the continuous delivery process starts by polling for new artifacts in the artifacts repository and when a new artifact is available it triggers the 1st phase of the deployment pipeline. The deployment pipeline has an associated deployment run book to deploy the application to an environment, when the application deployment is completed then an associated test pack will be executed, depending on the phase of the pipeline and it will return a subsequent pass if all tests complete successfully or a fail condition if tests have failed. The continuous delivery pipeline and all its test phases create feedback loops for deployment and test cycles which allows process improvement and refinement. A deployment pipeline works on the principle that we are proving that a release candidate is broken rather than proving it works, as we can't ever truly prove a release is perfect it is always a best effort.
 A continuous delivery pipeline should have a static run book of deployment activities which are common across all environments, with the only difference between deployments being the environment file or potentially the number of servers, which will be scaled up as we near production. The environment files job is to hold environment specific information, so all the information that makes an environment unique, which will be used to transform all application configuration files at deployment time and make them environment specific so they are configured correctly for that environment. The transformed application configuration files will allow an application to connect to environment specific database end-points, other environment specific applications, or simply define the URL for the application in an environment, or application run-time settings for that specific environment.
A continuous delivery pipeline should have a static run book of deployment activities which are common across all environments, with the only difference between deployments being the environment file or potentially the number of servers, which will be scaled up as we near production. The environment files job is to hold environment specific information, so all the information that makes an environment unique, which will be used to transform all application configuration files at deployment time and make them environment specific so they are configured correctly for that environment. The transformed application configuration files will allow an application to connect to environment specific database end-points, other environment specific applications, or simply define the URL for the application in an environment, or application run-time settings for that specific environment. 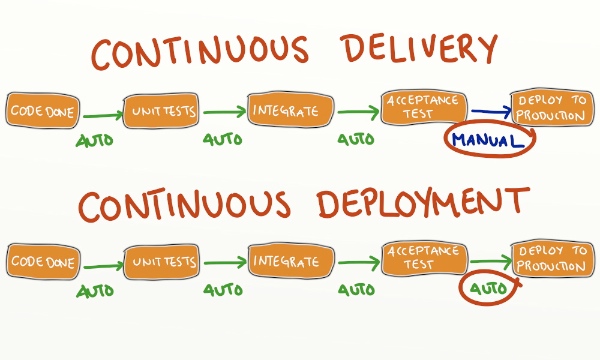 The environments and phases an application will traverse before being released to production can vary, typically a “Quality Assurance Component Test” environment which tests the application component in isolation, utilising stubbing to other components is used as a 1st quality gate prior to the application being integrated with other components. When completed it will automatically trigger the 2nd quality gate which will deploy the application to a “Quality Assurance Integration Test” environment where the application is put in an environment with other applications and a set of integration tests are run to test end to end integrations between the applications are working correctly. When completed the application may then be deployed to a 3rd quality gate “Performance Test” environment, which typically mimics the storage that is used in production, but at lesser scale, and runs a series of performance tests to make sure the new code change hasn’t introduced a performance degradation in the system. After continuous deployment to the automated test environments is complete, the release candidate awaits the manual button push to deploy it to production. To cut down time to market, some or all of these testing phases can be run in parallel and other test phases may be introduced for security, compliance or exploratory manual testing while the release candidate is awaiting production deployment. Later when the test gates have been hardened enough, and confidence has been built up in the processes, the manual button push before the production deployment can be removed and a company can instead implement continuous deployment instead of continuous delivery. Continuous deployment means that after the performance testing is quality gate is completed it will automatically trigger a deployment to production automatically, with the code check-in from continuous integration being the production deployment trigger, rather than a manual button press from a user after all test cycles have successfully completed.
The environments and phases an application will traverse before being released to production can vary, typically a “Quality Assurance Component Test” environment which tests the application component in isolation, utilising stubbing to other components is used as a 1st quality gate prior to the application being integrated with other components. When completed it will automatically trigger the 2nd quality gate which will deploy the application to a “Quality Assurance Integration Test” environment where the application is put in an environment with other applications and a set of integration tests are run to test end to end integrations between the applications are working correctly. When completed the application may then be deployed to a 3rd quality gate “Performance Test” environment, which typically mimics the storage that is used in production, but at lesser scale, and runs a series of performance tests to make sure the new code change hasn’t introduced a performance degradation in the system. After continuous deployment to the automated test environments is complete, the release candidate awaits the manual button push to deploy it to production. To cut down time to market, some or all of these testing phases can be run in parallel and other test phases may be introduced for security, compliance or exploratory manual testing while the release candidate is awaiting production deployment. Later when the test gates have been hardened enough, and confidence has been built up in the processes, the manual button push before the production deployment can be removed and a company can instead implement continuous deployment instead of continuous delivery. Continuous deployment means that after the performance testing is quality gate is completed it will automatically trigger a deployment to production automatically, with the code check-in from continuous integration being the production deployment trigger, rather than a manual button press from a user after all test cycles have successfully completed.
So how can agile help continuous integration and delivery? The truth is it can facilitate interactions between teams, allowing teams to see what other teams are working on, thus enabling them to work in a pro-active rather than reactive fashion and promotes collaboration, forward planning and eliminates team silos. It also helps to show where blockers reside across teams, the illustration of blockers can help with streamlining processes, and will help delivery teams only push a feature when everything has been lined up so the automated processes don’t break. In industry we wouldn’t knowingly make a change that would break a car manufacturing pipeline, by pushing broken changes down it, so why are continuous delivery pipelines for software any different? If we look at the software delivery life-cycle that continuous delivery or deployment helps facilitate, it encompasses contributions from teams from all parts of a business. In order for it to work correctly developers, quality assurance testers, performance testers, infrastructure teams, storage teams, hardware vendors, network engineers and security staff must all involved in this process and be key stakeholders. The main concepts that agile processes promote are realistic planning and consideration of others work, so this should be a perfect fit for cross functional teams.
 First let’s look at the infrastructure team as an example of how agile processes can help deliver software to market quicker. In order to build or deploy code we first need infrastructure, so the infrastructure team will need to know how much compute is required in a private cloud and be able to measure how much capacity they will need over time. Once a request has been made to the infrastructure team they may need to coordinate with the hardware vendors and make a purchase order or talk with the storage team to make sure there is enough space in the existing racks for the request. Even if you are buying more capacity in AWS or some other public cloud that means increasing the capacity quota, so public clouds don’t make this interaction go away, someone still needs to look after and approve company spend, public clouds may make reacting to needs for more capacity quicker to resolve, but it still doesn't fix the broken process in the team interaction, just because a problem takes less time to fix when using public cloud in a reactive manner doesn't make it any less of a process issue. When purchasing more kit for a private cloud a procurement process or purchase order will need to be completed which isn’t quick process, as it has associated hardware delivery timelines.
First let’s look at the infrastructure team as an example of how agile processes can help deliver software to market quicker. In order to build or deploy code we first need infrastructure, so the infrastructure team will need to know how much compute is required in a private cloud and be able to measure how much capacity they will need over time. Once a request has been made to the infrastructure team they may need to coordinate with the hardware vendors and make a purchase order or talk with the storage team to make sure there is enough space in the existing racks for the request. Even if you are buying more capacity in AWS or some other public cloud that means increasing the capacity quota, so public clouds don’t make this interaction go away, someone still needs to look after and approve company spend, public clouds may make reacting to needs for more capacity quicker to resolve, but it still doesn't fix the broken process in the team interaction, just because a problem takes less time to fix when using public cloud in a reactive manner doesn't make it any less of a process issue. When purchasing more kit for a private cloud a procurement process or purchase order will need to be completed which isn’t quick process, as it has associated hardware delivery timelines.  So how can agile help with this process and quicken time to market? If we have a scrum team just full of developers, they will typically think about developing the application and focus on the coding aspect, which is natural it is their bread and butter. However, If someone from the infrastructure team was a part of that scrum team too, they would be able to ask questions from another perspective, that may not be considered by developers. An infrastructure engineer is more likely to ask if we add this new feature will we need to scale out the infrastructure to support it? How much kit would you need for test environments? Would scaling out this application mean we need to scale out some of it's dependencies too. This would help avoid the scenario where developers finish coding the new feature, check it into source control, it hits the continuous delivery pipeline and they realise they don’t have enough kit to test the feature or deliver it to production, then they will have to send an email to the infrastructure team demanding new kit right away. This will only block the delivery of that feature to market, making everything wait on the slowest component which will be the order time of the kit from the hardware vendor. This in turn will frustrate the infrastructure team who will complain they weren’t notified early enough and the developers, who just want their feature to go live, will complain about the infrastructure team being a blocker, it will also cause strain between the Dev and Ops side of the business and also potentially involve an escalation to management.
So how can agile help with this process and quicken time to market? If we have a scrum team just full of developers, they will typically think about developing the application and focus on the coding aspect, which is natural it is their bread and butter. However, If someone from the infrastructure team was a part of that scrum team too, they would be able to ask questions from another perspective, that may not be considered by developers. An infrastructure engineer is more likely to ask if we add this new feature will we need to scale out the infrastructure to support it? How much kit would you need for test environments? Would scaling out this application mean we need to scale out some of it's dependencies too. This would help avoid the scenario where developers finish coding the new feature, check it into source control, it hits the continuous delivery pipeline and they realise they don’t have enough kit to test the feature or deliver it to production, then they will have to send an email to the infrastructure team demanding new kit right away. This will only block the delivery of that feature to market, making everything wait on the slowest component which will be the order time of the kit from the hardware vendor. This in turn will frustrate the infrastructure team who will complain they weren’t notified early enough and the developers, who just want their feature to go live, will complain about the infrastructure team being a blocker, it will also cause strain between the Dev and Ops side of the business and also potentially involve an escalation to management.  It really isn’t necessary, to mitigate this an infrastructure engineer could be part of the scrum team and involved in planning of the feature, so while the feature is being developed they can line up the necessary compute kit. However, sometimes this isn’t practical or feasible for infrastructure engineers to join all the development teams scrums and stand-ups in large businesses. Instead a better use of time would be for scrum masters to train developers to consider infrastructure requirements from the outset in every user story. If more infrastructure is required they can assign a task on that features user story for the infrastructure team and talk with the team and have them estimate the duration. The user story will then have a dependency on the infrastructure resource who can carry out the necessary kit order for new compute while the feature is still being developed. This moves the business into pro-active mode as opposed to reactive mode, this way a user story and feature can’t be set to done, until the necessary kit is available to deploy it to test environments or production. A user story is then “Done” in agile terms when it is ready for production deployment. This way the feature isn’t checked in to trunk until the kit is made available for the test and production environments, so until then, we don’t want to trigger the continuous delivery process and block the pipeline with something that isn’t ready to be delivered yet. This is a very simple solution and will keep everyone informed and make sure the time to market is as quick as possible but it needs the buy in from all the teams to work.
It really isn’t necessary, to mitigate this an infrastructure engineer could be part of the scrum team and involved in planning of the feature, so while the feature is being developed they can line up the necessary compute kit. However, sometimes this isn’t practical or feasible for infrastructure engineers to join all the development teams scrums and stand-ups in large businesses. Instead a better use of time would be for scrum masters to train developers to consider infrastructure requirements from the outset in every user story. If more infrastructure is required they can assign a task on that features user story for the infrastructure team and talk with the team and have them estimate the duration. The user story will then have a dependency on the infrastructure resource who can carry out the necessary kit order for new compute while the feature is still being developed. This moves the business into pro-active mode as opposed to reactive mode, this way a user story and feature can’t be set to done, until the necessary kit is available to deploy it to test environments or production. A user story is then “Done” in agile terms when it is ready for production deployment. This way the feature isn’t checked in to trunk until the kit is made available for the test and production environments, so until then, we don’t want to trigger the continuous delivery process and block the pipeline with something that isn’t ready to be delivered yet. This is a very simple solution and will keep everyone informed and make sure the time to market is as quick as possible but it needs the buy in from all the teams to work. Agile can help quality assurance teams in a similar way by involving testers in sprint planning instead of having a developer write a piece of code and then hand it off to a developer to test. This hand-over in waterfall processes is sometimes referred to as “throwing it over the wall” in technology, so typical scenarios are developers write code or features in isolation, check it in, it hits the first quality assurance environment and the test gate fails with lots of quality assurance tests broken. This is because the quality assurance teams test packs haven’t been adequately updated to cater for the new feature as they didn’t know what was coming down the pipeline, this has led to lots of broken tests in the component and integration test packs, so the feature is blocked from being delivered to production until those tests are retrospectively fixed. Even more frustratingly for the developer the new feature may even be operating correctly, but the quality assurance team need a green test run before they can sign off the release.
Agile can help quality assurance teams in a similar way by involving testers in sprint planning instead of having a developer write a piece of code and then hand it off to a developer to test. This hand-over in waterfall processes is sometimes referred to as “throwing it over the wall” in technology, so typical scenarios are developers write code or features in isolation, check it in, it hits the first quality assurance environment and the test gate fails with lots of quality assurance tests broken. This is because the quality assurance teams test packs haven’t been adequately updated to cater for the new feature as they didn’t know what was coming down the pipeline, this has led to lots of broken tests in the component and integration test packs, so the feature is blocked from being delivered to production until those tests are retrospectively fixed. Even more frustratingly for the developer the new feature may even be operating correctly, but the quality assurance team need a green test run before they can sign off the release.  Operating in this manner means the quality assurance team don’t actually know what are actual genuine errors and what are errors caused by out of date test packs and this completely compromises the value of the test and feedback loop. To mitigate this quality assurance testers should work as part of the scrum team, so they can create tests while the developers are developing the new feature. As a bi-product this also helps cross skill developers to write automated tests for quality assurance test packs. This is so that when a user story is created, tasks to create the feature and associated feature tests are created together, and testing is not an after thought. This way the quality assurance testers are well informed of the new features and can adequately update their quality assurance test packs before the feature is checked in to the trunk branch in source control. The trunk branch will trigger the continuous integration process and associated continuous delivery pipeline, so before this happens a quality assurance engineer will need the time required to remove any out of date regression tests or tweaking them accordingly which is all planned work as part of the sprint. The quality assurance tester will also iteratively run the feature tests, while the feature is being developed by the developer, to make sure quality assurance is done prior to check-in so once the feature is ready it only needs to pass all regression tests as part of the continuous delivery pipeline. This means testing is not treated as an after thought and is an integral piece of software delivery.
Operating in this manner means the quality assurance team don’t actually know what are actual genuine errors and what are errors caused by out of date test packs and this completely compromises the value of the test and feedback loop. To mitigate this quality assurance testers should work as part of the scrum team, so they can create tests while the developers are developing the new feature. As a bi-product this also helps cross skill developers to write automated tests for quality assurance test packs. This is so that when a user story is created, tasks to create the feature and associated feature tests are created together, and testing is not an after thought. This way the quality assurance testers are well informed of the new features and can adequately update their quality assurance test packs before the feature is checked in to the trunk branch in source control. The trunk branch will trigger the continuous integration process and associated continuous delivery pipeline, so before this happens a quality assurance engineer will need the time required to remove any out of date regression tests or tweaking them accordingly which is all planned work as part of the sprint. The quality assurance tester will also iteratively run the feature tests, while the feature is being developed by the developer, to make sure quality assurance is done prior to check-in so once the feature is ready it only needs to pass all regression tests as part of the continuous delivery pipeline. This means testing is not treated as an after thought and is an integral piece of software delivery. Agile can work the same way for network engineers, security engineers or any other team for that matter. Assigning tasks to network engineers as part of a sprint will involve them earlier in the process and the same can be said by security. A group of security champions can monitor user stories that are being planned and raise any security concerns as part of the design process, as opposed to blocking changes going live once features have already been developed and being seen as giving developers more work. It is a common sense approach, to involve every team you need up-front, as opposed to sitting in a silo and not discussing requirements and needs with other teams. Involving everyone in the process of sprint planning, so all requirements and considerations are made at the start of the process is integral for continuous delivery to be successful. This means additional work doesn’t need to be done in an unplanned fashion and all work is considered from the outset. This helps avoid delays delivering the product to market which minimises work in progress (WIP), instead all WIP is tracked as part of sprints and encapsulated by the scrum teams and therefore visible to the business. Any tasks not feeding into sprints is hidden WIP, which will slow down delivery of features to market, if it isn’t transparent it can’t be streamlined and improved upon.
Agile can work the same way for network engineers, security engineers or any other team for that matter. Assigning tasks to network engineers as part of a sprint will involve them earlier in the process and the same can be said by security. A group of security champions can monitor user stories that are being planned and raise any security concerns as part of the design process, as opposed to blocking changes going live once features have already been developed and being seen as giving developers more work. It is a common sense approach, to involve every team you need up-front, as opposed to sitting in a silo and not discussing requirements and needs with other teams. Involving everyone in the process of sprint planning, so all requirements and considerations are made at the start of the process is integral for continuous delivery to be successful. This means additional work doesn’t need to be done in an unplanned fashion and all work is considered from the outset. This helps avoid delays delivering the product to market which minimises work in progress (WIP), instead all WIP is tracked as part of sprints and encapsulated by the scrum teams and therefore visible to the business. Any tasks not feeding into sprints is hidden WIP, which will slow down delivery of features to market, if it isn’t transparent it can’t be streamlined and improved upon.
As humans we like to know what is going on and what is planned and agile is a delivery pipeline in it’s own right, as it stores up all the WIP that is required to allow code to be pushed to live using continuous delivery pipelines, but it has to include everyone in a business or it just won’t work. Really the principles and process to deliver code to production are very simple when done correctly, but people are complex and they make mistakes, but iterating these processes over time will make everyone consider the end to end process and become better at their job. If someone in technology cannot explain to you the development life-cycle process of the business then how can they be part of any team to make it better and easier. That is the first step, go back to basics, think what we are trying to achieve and throw away all the unnecessary bureaucratic processes that just don’t matter. If you don’t do this your competitor might and then you won’t be able to compete, so lean processes are so important for companies to remain competitive. If two companies of equal ability are competing to deliver a new product to market quicker and one has fully waterfall business processes and the other has truly agile business processes not confined to just the development teams, I know who my money would be on being able to deliver the product to market faster. Agile and continuous delivery isn’t just for developers it is for everyone and it is truthful and open and that's why big businesses were scared of it for so long, it shows what everyone is doing in detail which can be scary at first for many. However, if your company isn't embracing agile and continuous delivery then it is time to start, it just makes everything so much easier and to fix everything we need to be honest.












{kind=link}